RabbitMQを 3台のクラスタにして冗長化しましたので、冗長性など確認してみます。
「RabbitMQでメッセージを受け渡し」で RabbitMQのインストールをし、
「RabbitMQのクラスタ化(前編)」でサーバーを 2台使って冗長化し、
「RabbitMQのクラスタ化(中編)」でデータが冗長化されているキューを作成しました。(3台のクラスタになりました)
ここではでき上がった環境で冗長化のテストをします。
現在の環境はこんな感じです。
クォーラムキューは、クラスタ内全てのノードに同じメッセージデータがコピー(レプリケーション)されている形態を取ります。
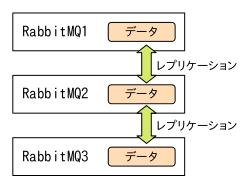
すなわち、1〜3のどれにアクセスしても、データ投入(パブリッシュ)・データ取得(コンシューム)できるはずなんです。
まずは正常ケース(1〜3まで稼働中)を試してみます。
[send.py]
#!/usr/bin/python3
import pika
connection = pika.BlockingConnection( pika.ConnectionParameters( host="RabbitMQ1", virtual_host="/testvhost", credentials=pika.PlainCredentials('subro', 'password') ))
channel = connection.channel()
channel.basic_publish(exchange='',
routing_key='test',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
ピンクの所で[RabbitMQ1]を指定してパブリッシュをしています。
次は[RabbitMQ3]からコンシュームするスクリプトを実行します。
[receive.py]
#!/usr/bin/python3
import pika, sys, os
def main():
connection = pika.BlockingConnection( pika.ConnectionParameters( host="RabbitMQ3", virtual_host="/testvhost", credentials=pika.PlainCredentials('subro', 'password') ))
channel = connection.channel()
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(queue='test', on_message_callback=callback, auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
print('Interrupted')
try:
sys.exit(0)
except SystemExit:
os._exit(0)
ピンクの所で[RabbitMQ3]を指定しています。
想定通り上手くコンシュームできました。
データレプリケーションされているかは別として、クラスタとして動いているのは間違いありません。
さて、ここでクォーラムキューがクラスタのどこまでの障害に耐え得るかをおさらいします。
以下のドキュメントに表があります。
Fault Tolerance and Minimum Number of Replicas Online
これによると、3台構成の場合は 1台の故障まで耐えるようです。
この条件を前提に以下の実験を行っていきます。
データがちゃんと各ノードにレプリケーションされているかを確認するため、順番で操作してみます。
- [RabbitMQ2][RabbitMQ3]を停止
(1台だけの場合の動作を見る) - [RabbitMQ1]にパブリッシュ
- [RabbitMQ2][RabbitMQ3]を開始
(データがレプリケーションされると思う) - {RabbitMQ1]を停止
- [RabbitMQ3]からコンシューム
作業1は疑似障害を起こすものです。
VMware Workstation Playerの「ゲストのシャットダウン」という機能で強制的に仮想マシンを落としました。
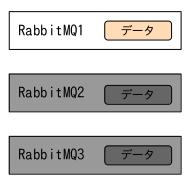
疑似障害としてはちょっと弱いので、是非電源ばっつん機能を作って欲しいです。
作業2で[RabbitMQ1]にパブリッシュしました。
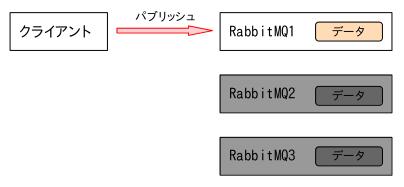
ここで「おやっ?」となりました。
パブリッシュはするのですが、スクリプトが終了せず待っています。
3台構成で許される障害は 1台までとありましたから、2台目が稼働していないとパブリッシュを待機させる(エラーにならない)ようです。
作業3の作業としてパブリッシュしているスクリプトはそのまま[RabbitMQ2]だけ起動してみました。
しますと、パブリッシュするスクリプトは正常終了しました。
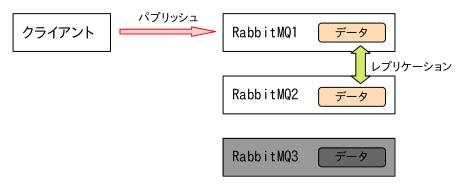
少なくともこの時点で[RabbitMQ3]にはデータはないはずです。
[RabbitMQ3]を起動します。
4の作業で[RabbitMQ1]で強制停止の疑似障害を起こします。
5の作業で[RabbitMQ3]からコンシュームします。
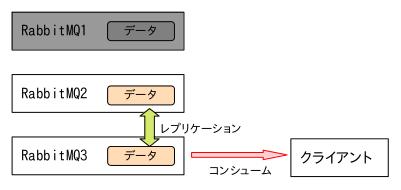
上手くデータを取得できました。
できました…できましたけど、クォーラムキューがクラスタ環境で動作して、1台の障害に耐えているのは分かりましたが、[RabbitMQ2]が稼働したままだから [RabbitMQ3]にデータがレプリケーションされている事の確認になっていませんよね。
クォーラムキューは 1台きりでの片肺運転みたいな動作はしないようですので、理屈上はこのやり方ではレプリケーションの確認はできませんね…。
若干思うところを残しながらですが、RabbitMQのクラスタ環境の動作確認はこんな感じかと思います。
RabbitMQのクラスタ構築自体はそんなに難しくありません。
でも、障害時の運用となると、複数台にまたがるデータキューイングの動作上の理屈を学ばないといけない感じで、その方が余程難しいように思います。
それでもこの環境を展開できれば、設計次第でかなり柔軟にシステム間の連携をすることができるようになると思いました。
障害時運用が難しい?
だからパブリッククラウドが提供するキューイングサービスが人気があるんでしょうねぇ。
「RabbitMQのクラスタ化(番外編)」では障害時にクライアントはどうやってクラスタに繋ぎにいくのかを書いています。