サーバーメトリクスを取得するのは良いけど、それはあくまで手段で、それを使ってどう判断するかは別な話。
このホームページでは、サーバー監視に関係するネタも少ないですがいくつか書いています。
サーバーの運用をする場合、障害発生を(なるべく)事前にキャッチするために様々な手を打つんですが、その一つがサーバーのハードウェアリソースの使用状況の監視があります。
主に CPU・メモリ・ストレージ・ネットワークの 4種で、OSにはこれらの使用状況をリアルタイムに取得できる手段が用意されています。
そこで得られるものは純粋な数値(データ)なので、人間に見やすいようグラフ化するのが常套手段で、Grafanaのようなデータを元に綺麗なダッシュボードを表示するソフトが人気があります。
ただそういった手段が目的になっている人を散見するのも事実で、グラフは作ってからが本番ということを忘れてはいけないと思います。
こう思うところは色々とありますが、例を一つあげましょう。
あるサーバー機(またはクラウドの仮想サーバーとか)の CPU負荷のグラフがこうなっていたとします。
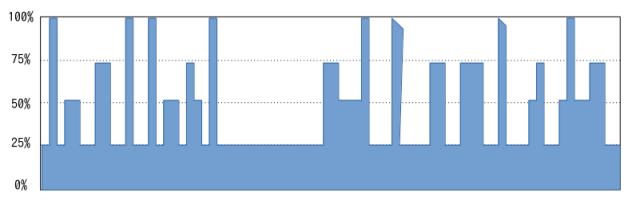
これって CPUコアを4つ持っているサーバーなんですが障害状態が見えています。
単純に考えると「CPU使用率が 100%を突いている箇所が何箇所もあるのでCPUパワーが足りていない」となりますけど、実際は「あるプログラムが永久ループに陥っている」のです。
マルチコアの CPUを使っている場合、上のように 100%をコア数で割った数値毎の階段状に使用率が出ることが多いです。
上のグラフでは 25%の使用率分が下駄履かせたようになっているのは 1コア分が延々と使い続けていることを意味します。
コンピューターの仕組みから言うと、余程長時間の計算に特化したプログラムでも動かさない限りはグラフがこういう絵面にはなりません。
一方で 100%を突いている点に関しては、回数が少ない事から必ずしもパワー不足とも言えないと判断しても良いと思います。
サーバー監視でよくやるのは、ハードウェアリソース使用状況に閾値(例えば80%)を設けて、それを越えたらメール等で通知するという手法ですが、単純にそれだけだと上のケースは漏らしてしまいますね。
それどころか CPU増設を提案してしまうというおまけつき。
サーバーリソース監視については、余り単純ではなく他の要素との組み合わせで判断するべきなので、コンピューターの仕組みからの理解が欲しいところで、決してグラフ一つで判断できるものではないというのが私の経験からの想いです。
非機能要件定義では障害検知条件を表しますが、条件の設定にはシステムの利用状況に関する分析が必須です。
こればかりは実際にシステム利用が開始されてから徐々に詰めていく他なかった経験しかなく、計画してもまず思った通りにはなりませんでしたね。
なので非機能用件として事前に決めることに拘泥するのは時間やコストの無駄にも思えました。
長い経験で辿り着いた結論は、サーバーの健康状態の時のグラフとの乖離があるかどうかでした。
大体のシステムは負荷推移が日次でパターン化されてくると思います。
休みがある顧客の場合は、週次でも変化があるかも知れません。
いずれにしても、サーバー負荷を長らく記録しておくと、あるパターンが浮かび上がってきます。
それがサーバーが問題なく業務をこなしていた健康状態で、そこから大きく逸脱する負荷がかかるのは何かおかしなことが起きている証、そんな感じです。
あのブログやこのブログで紹介されているのはカッコ良いダッシュボードに直近 1時間のサーバー負荷がリアルタイムに表示されるものが多い印象ですけど、B2Cの WEBフロントのサーバーを対象としているものだろうな〜と思っています。
あれはそういう用途のサーバーだからですね。
「自分が運用しているサーバーは普段どう使われているか?」、これがサーバー負荷を記録して、それをグラフ化して、の後に必要になるキーワードです。