Ubuntu Serverに Redisのクラスタ環境を作ってみます。
「Redisクラスタ 1」で、これから環境構築する上で出てくる用語について説明し、
「Redisクラスタ 2」では、実際に環境構築しました。
ここでは Redisクラスタに対して、Pythonでデータを書いたりしてみます。
1.環境
クライアントには以下のものを使います。
2024年1月27日時点での最新版です。
- Lubuntu 22.04.3
- Python 3.10.12
- (Pythonのモジュール)redis-5.0.1
Pythonで Redis謹製の「redis-py」というモジュールが使えることになっていますので、これをインストールしておきます。
ちょっと前まで「redis-py-cluster」というものだったのですが、現在は「redis-py」に統合されたようです。
subro@Lubuntu2204:~$ python3 -m pip install redis
Defaulting to user installation because normal site-packages is not writeable
Collecting redis
Downloading redis-5.0.1-py3-none-any.whl (250 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 250.3/250.3 KB 1.5 MB/s eta 0:00:00
Collecting async-timeout>=4.0.2
Downloading async_timeout-4.0.3-py3-none-any.whl (5.7 kB)
Installing collected packages: async-timeout, redis
Successfully installed async-timeout-4.0.3 redis-5.0.1
インストールできました。
2.Pythonでの書き込み
Redisのマニュアルにクラスタへのアクセスの仕組みはクライアント側で対応しなければならない旨が書いてありまして、単体で立っている Redisサーバーと Redisクラスタですと、接続方法に違いがあります。
redis-pyで Resisクラスタへの接続については redis-pyのマニュアルの以下の段落に書いてあります。
Clustering
ここにある説明を元に Redisクラスタに 10万件のデータを書き込む Pythonコードを書いてみました。
データはこんな風になるはず。
| キー | 値 |
|---|---|
| 000001 | 1 |
| 000002 | 2 |
| 中略 | 中略 |
| 099999 | 99999 |
| 100000 | 100000 |
このスクリプトでは [redis.cluster.RedisCluster]クラスを使っています。
接続先がクラスタではない場合は [Redis]クラスを使うようです。
[test.py]
from redis.cluster import RedisCluster as Redis
rc = Redis.from_url("redis://redis1:6379/0")
for i in range(1, 100001):
rc.set( f'{i:06}', i )
ちなみに書いたデータを削除するコードはこうです。
from redis.cluster import RedisCluster as Redis
rc = Redis.from_url("redis://redis1:6379/0")
for i in range(1, 100001):
rc.delete( f'{i:06}' )
実行する前に、[redis1]サーバーにて、クラスタ全体のマスターノードの状態を取っておきました。
各ノードにはまだデータがありません。
subro@redis1:~$ redis-cli --cluster info localhost:6379
localhost:6379 (b6cc0a3a...) -> 0 keys | 5461 slots | 1 slaves.
192.168.1.157:6379 (9260c0c6...) -> 0 keys | 5462 slots | 1 slaves.
192.168.1.158:6379 (840b3a45...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
Lubuntuで Pythonスクリプトを実行します。
subro@Lubuntu2204:~/work/python/redis$ python3 test.py
実行できました。
再度 [redis1]サーバーにて、マスターノードの状態を取ってみます。
subro@redis1:~$ redis-cli --cluster info localhost:6379
localhost:6379 (b6cc0a3a...) -> 33304 keys | 5461 slots | 1 slaves.
192.168.1.157:6379 (9260c0c6...) -> 33388 keys | 5462 slots | 1 slaves.
192.168.1.158:6379 (840b3a45...) -> 33308 keys | 5461 slots | 1 slaves.
[OK] 100000 keys in 3 masters.
6.10 keys per slot on average.
概ね 1/3くらいずつ分割されていますが、完全に按分ではないですね。
3.Redisクライアントから Redisクラスタへのアクセスについて
データを書き込んだ相手はマスターノードの 3台なんですが、スクリプトに書いている接続先は [redis1]サーバーだけでした。
こういう動きをしているのか?と思いきや違うようです。
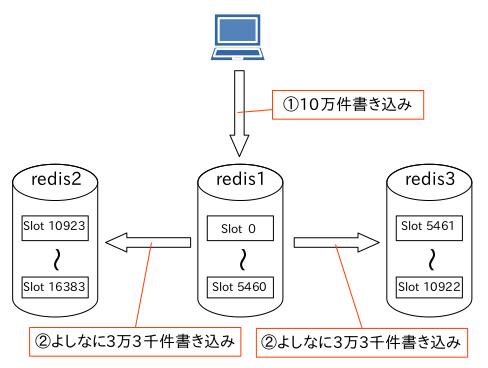
そうではなく、このようですよ。
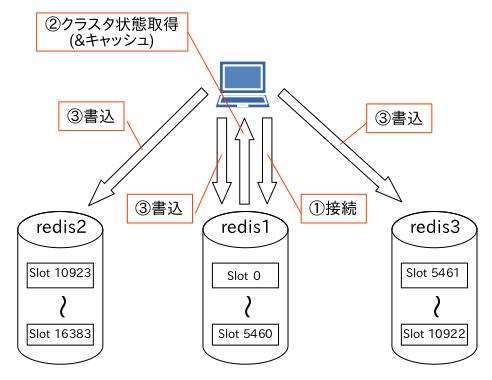
なので、すべてのノードのデータ用ポートはクライアントに対して開いていないといけないのだと、マニュアルに書いてあった気がします。
検索の時も同じなので、ファイアウォールの設定ではこの仕組みを忘れないようにしましょう。
なお [redis.cluster.RedisCluster]クラスを使って作ったセッションは、デフォルトでコネクションプールが使われているとのことです。
==========
これでスピードアップのためにデータがシャーディング(水平分割)されている様子を確認することができました。
やり込むほどに面白い Redisであります。
次回「Redisクラスタ 4」では冗長化の実験をします。