Ubuntu Serverに Redisのクラスタ環境を作ってみます。
「Redisクラスタ 1」で、これから環境構築する上で出てくる用語について説明し、
「Redisクラスタ 2」で、実際に環境構築し、
「Redisクラスタ 3」で、データがシャーディングされる様子を確認しました。
ここでは Redisクラスタの冗長性・耐障害性の確認をしてみます。
1.環境
現在のクラスタの構成を確認します。
(レプリカノードの [redis6]サーバーで実行しても全体の情報を得られています。)
subro@redis6:~$ redis-cli --cluster check localhost:6379
192.168.1.157:6379 (9260c0c6...) -> 0 keys | 5462 slots | 1 slaves.
192.168.1.156:6379 (b6cc0a3a...) -> 0 keys | 5461 slots | 1 slaves.
192.168.1.158:6379 (840b3a45...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node localhost:6379)
S: 8587523a96c94b0480f56c5b431e818f9a13cff2 localhost:6379 ← [redis6]
slots: (0 slots) slave
replicates 9260c0c69d53b48b7cd00fa81c05349bf9c9b979
M: 9260c0c69d53b48b7cd00fa81c05349bf9c9b979 192.168.1.157:6379 ← [redis2]
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: b6cc0a3aaddea023672e913070ef8f906dc353bc 192.168.1.156:6379 ← [redis1]
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 0d22119ac60324251935a01af50514b117053b94 192.168.1.160:6379 ← [redis5]
slots: (0 slots) slave
replicates b6cc0a3aaddea023672e913070ef8f906dc353bc
M: 840b3a45d130e40c02f47bfd2765510aa4db1c92 192.168.1.158:6379 ← [redis3]
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9cef886d91c9f4eb6b9ea2437b1187c9838fe91c 192.168.1.159:6379 ← [redis4]
slots: (0 slots) slave
replicates 840b3a45d130e40c02f47bfd2765510aa4db1c92
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
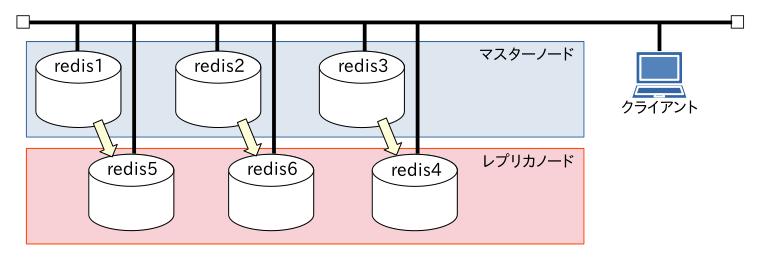
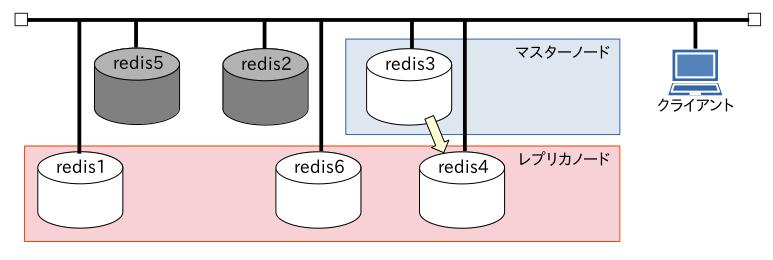
ネットワーク的にこのような構成になっていて、全て同じネットワークセグメント上にあります。
マスターノードとレプリカノードの紐付けは黄色い矢印の通り。
以下の Pythonスクリプトで 10万件のデータを書きながら擬似的に障害を起こしていきます。
このスクリプトの接続先は レプリカノードの [redis6]サーバーにしてみました。
[test.py]
from redis.cluster import RedisCluster as Redis
rc = Redis.from_url("redis://redis6:6379/0")
for i in range(1, 100001):
rc.set( f'{i:06}', i )
2.マスターノード 1台の停止
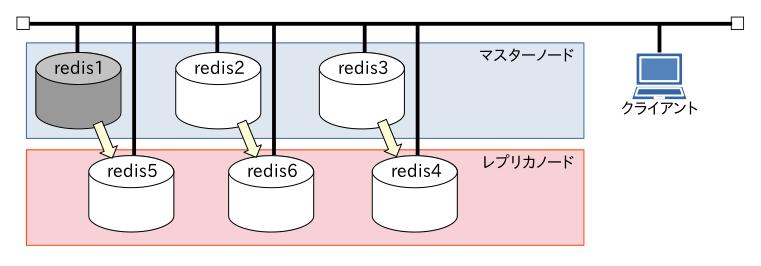
データを書き込みながら、マスターノードの [redis1]サーバーをシャットダウンしてみます。
図的にはこうです。
subro@redis1:~$ sudo poweroff
Pythonスクリプトはエラーになりました。
subro@Lubuntu2204:~/work/python/redis$ python3 test.py
〜〜〜 中略 〜〜〜
redis.exceptions.ConnectionError: Error 111 connecting to 192.168.1.156:6379. Connection refused.
クラスタの状態を確認してみます。
subro@redis6:~$ redis-cli --cluster check localhost:6379
Could not connect to Redis at 192.168.1.156:6379: No route to host
192.168.1.157:6379 (9260c0c6...) -> 4304 keys | 5462 slots | 1 slaves.
192.168.1.160:6379 (0d22119a...) -> 4296 keys | 5461 slots | 0 slaves.
192.168.1.158:6379 (840b3a45...) -> 4301 keys | 5461 slots | 1 slaves.
[OK] 12901 keys in 3 masters.
0.79 keys per slot on average.
>>> Performing Cluster Check (using node localhost:6379)
S: 8587523a96c94b0480f56c5b431e818f9a13cff2 localhost:6379 ← [redis6]
slots: (0 slots) slave
replicates 9260c0c69d53b48b7cd00fa81c05349bf9c9b979
M: 9260c0c69d53b48b7cd00fa81c05349bf9c9b979 192.168.1.157:6379 ← [redis2]
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 0d22119ac60324251935a01af50514b117053b94 192.168.1.160:6379 ← [redis5]
slots:[0-5460] (5461 slots) master
M: 840b3a45d130e40c02f47bfd2765510aa4db1c92 192.168.1.158:6379 ← [redis3]
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9cef886d91c9f4eb6b9ea2437b1187c9838fe91c 192.168.1.159:6379 ← [redis4]
slots: (0 slots) slave
replicates 840b3a45d130e40c02f47bfd2765510aa4db1c92
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
スクリプトの方はエラー発生時点で停止していて、書き込みができるまで待ってはいませんね。
[redis1]サーバーのレプリケーション先だった [redis5]サーバーがマスターノードに昇格しています。
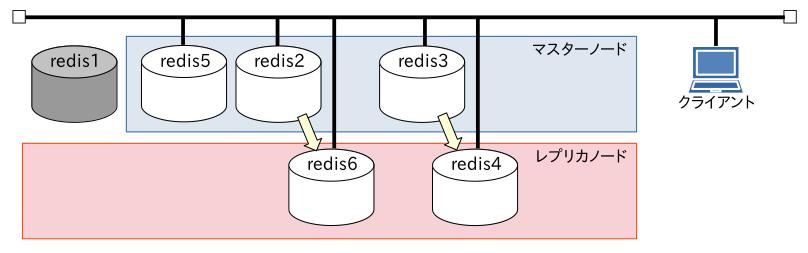
[
[redis1]サーバーを起動してみます。
クラスタの状態を確認してみます。
subro@redis6:~$ redis-cli --cluster check localhost:6379
192.168.1.157:6379 (9260c0c6...) -> 4304 keys | 5462 slots | 1 slaves.
192.168.1.160:6379 (0d22119a...) -> 4296 keys | 5461 slots | 1 slaves.
192.168.1.158:6379 (840b3a45...) -> 4301 keys | 5461 slots | 1 slaves.
[OK] 12901 keys in 3 masters.
0.79 keys per slot on average.
>>> Performing Cluster Check (using node localhost:6379)
S: 8587523a96c94b0480f56c5b431e818f9a13cff2 localhost:6379 ← [redis6]
slots: (0 slots) slave
replicates 9260c0c69d53b48b7cd00fa81c05349bf9c9b979
M: 9260c0c69d53b48b7cd00fa81c05349bf9c9b979 192.168.1.157:6379 ← [redis2]
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: b6cc0a3aaddea023672e913070ef8f906dc353bc 192.168.1.156:6379 ← [redis1]
slots: (0 slots) slave
replicates 0d22119ac60324251935a01af50514b117053b94
M: 0d22119ac60324251935a01af50514b117053b94 192.168.1.160:6379 ← [redis5]
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 840b3a45d130e40c02f47bfd2765510aa4db1c92 192.168.1.158:6379 ← [redis3]
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9cef886d91c9f4eb6b9ea2437b1187c9838fe91c 192.168.1.159:6379 ← [redis4]
slots: (0 slots) slave
replicates 840b3a45d130e40c02f47bfd2765510aa4db1c92
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
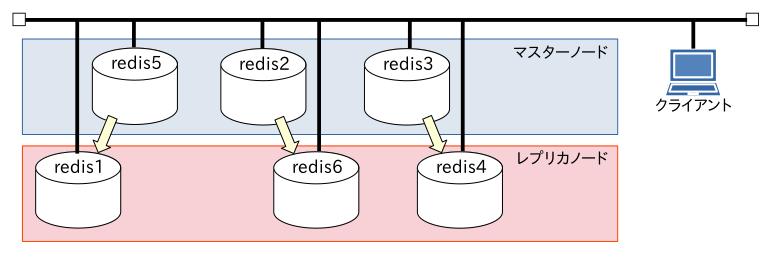
[redis1]サーバーは自動的にクラスタに戻ってきましたが、[slave](ここはまだ「replication」に変えられていませんね…)になりました。
一度マスターノードになったらそのままなんですね。
3.マスターノード 2台の停止
今度はマスターノードの [redis2]サーバー・[redis5]サーバーを同時に止めてみます。
理屈で言うと、Redisクラスタはサービス停止となるはずです。
一度データを空にして、また 10万件のデータを書きながら 2つのサーバーをシャットダウンします。
Pythonスクリプトは予想通りエラーになりました。
クラスタの状態を確認してみました。
ここだけ出力はオリジナルの色に似せてみました。
subro@redis6:~$ redis-cli --cluster check localhost:6379
Could not connect to Redis at 192.168.1.157:6379: No route to host
Could not connect to Redis at 192.168.1.160:6379: No route to host
*** WARNING: localhost:6379 claims to be slave of unknown node ID 9260c0c69d53b48b7cd00fa81c05349bf9c9b979.
*** WARNING: 192.168.1.156:6379 claims to be slave of unknown node ID 0d22119ac60324251935a01af50514b117053b94.
192.168.1.158:6379 (840b3a45...) -> 7954 keys | 5461 slots | 1 slaves.
[OK] 7954 keys in 1 masters.
0.49 keys per slot on average.
>>> Performing Cluster Check (using node localhost:6379)
S: 8587523a96c94b0480f56c5b431e818f9a13cff2 localhost:6379
slots: (0 slots) slave
replicates 9260c0c69d53b48b7cd00fa81c05349bf9c9b979
S: b6cc0a3aaddea023672e913070ef8f906dc353bc 192.168.1.156:6379
slots: (0 slots) slave
replicates 0d22119ac60324251935a01af50514b117053b94
M: 840b3a45d130e40c02f47bfd2765510aa4db1c92 192.168.1.158:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9cef886d91c9f4eb6b9ea2437b1187c9838fe91c 192.168.1.159:6379
slots: (0 slots) slave
replicates 840b3a45d130e40c02f47bfd2765510aa4db1c92
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.
最後の行にエラーが出るようになりました。
この後に残ったマスターノードの [redis3]サーバーを使い、1件1件キーを変えながら生きているマスターノードだけは書き込みができるのか確認しても良いのですが、実務では余り意味が無さそうなのでやりません。
4.ノードタイムアウトについて
ここからはマニュアルに書いてある内容の解説になります。
「Redisクラスタ 2」で Resisクラスタの設定をした際に、[/etc/redis/redis.conf]ファイルに対して以下のような変更を加えました。
#cluster-node-timeout 15000
↓
cluster-node-timeout 5000 ← コメントアウト[#]を外して有効化し、5000(ms)に変更します。
マニュアルではこの [cluster-node-timeout]値は、Redisクラスタの運用において非常に重要なものなのだそうです。
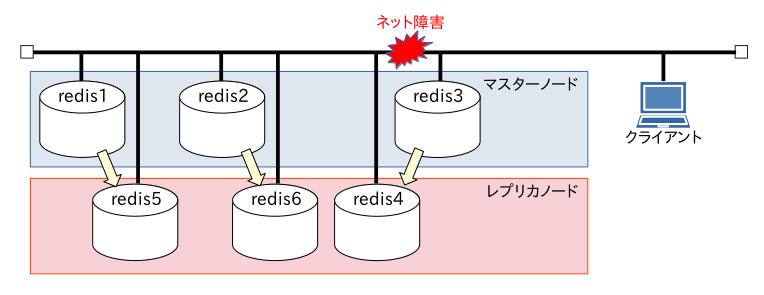
物理ネットワークでこんな状況が起きるとも思えませんが、マニュアルにある障害の例を今回の実験の絵で表現するとこんな感じになります。
その際の障害と [cluster-node-timeout]値の関係はこういうことのようです。

ネットワークの瞬断(すぐに直る)などを除外しつつ、どれだけ早くレプリカをマスターに昇格させるかの値(≒サービス復旧までの時間)、そういう認識になりました。
[cluster-node-timeout]値を超えてからネットワークが復旧すると、エラー状態とマークされている [redis3]サーバーはレプリカノードとなってしまいます。
この際に以下の図のように失われるデータが出ますので注意が必要です。

このようにマスターノード群がネットワーク的に分断されてしまった状況下で両方が稼働してしまうのを「スプリットブレイン」と呼びます。
障害復旧時に上図のように失われるデータが発生してしまう可能性があるので、マスターノード数が過半数になる方を活かして反対側はエラーとなって停止する仕組みにするのが一般のようです。
だからこの手のソフトでは、マスターノード数を 3つ以上の奇数で構成するのが普通です。
==========
[cluster-node-timeout]値の適正な値はシステム個々に違うと思うので、決めるのが難しそうですね。
スプリットブレインは Elasticsearchで初めて知った概念でしたが、この手の分散処理機構ではついて回る汎用的な知識なので、ここでは「Redisの〜」というより、この考え方を覚えてもらいたいですね。
ここまで Redisクラスタのお勉強をしてみて、次回は AWSの Amazon ElastiCache for Redis についてなにか書いてみようと思います。
つづく。